[AINews] Qwen 2 beats Llama 3 (and we don't know how) • ButtondownTwitterTwitter
Chapters
AI Twitter Recap
AI Discord Recap
AI Community Discussions and Events
Discussion of Various Topics in Discord Channels
LLM Finetuning - Jason Improving RAG
Optimizing RAG and LLM Finetuning Discussions
LLM Finetuning (Hamel + Dan) Discussions
Unsloth AI (Daniel Han) Discussions
Implementing RAG in Mistral AI
Eleuther Research
Eleuther, Perplexity AI, and Perplexity AI ▷ Sharing
Modular (Mojo 🔥)
Dynamic libpython Update and Cohere Highlights
Nous Research AI World-Sim
Qwen2 Launch and LangChain AI Discussions
Newsletter and Sponsor
AI Twitter Recap
All recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
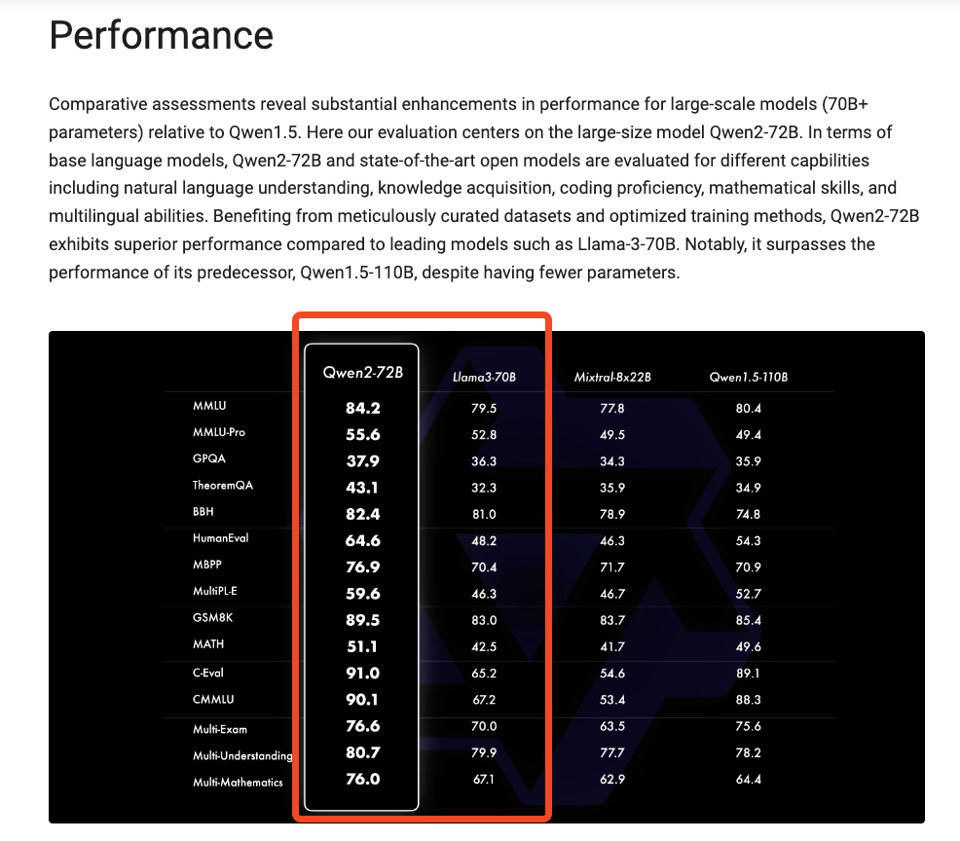
Qwen2 Open-Source LLM Release
- Qwen2 models ### Summary:
AI Discord Recap
A summary of summaries covering various AI-related developments and discussions shared on Discord. Highlights include insights into LLM and model performance innovations such as the Qwen2 models and Stable Audio Open 1.0, discussions on fine-tuning and prompt engineering challenges, and open-source AI developments like Prometheus-2 for evaluating RAG apps and the launch of OpenDevin. The section also delves into deployment, inference, and API integrations, with topics like Perplexity Pro's enhanced search abilities, Modal's deployment and privacy concerns, and technical insights on OpenRouter.
AI Community Discussions and Events
Stable Diffusion 3 Speculation:
Community buzz surrounds the anticipated release, with speculation about features and timelines, as detailed in various Reddit threads.
Human Feedback Foundation Event on June 11:
Upcoming discussions on integrating human feedback into AI, featuring speakers from Stanford and OpenAI with recordings available on their YouTube channel.
Qwen2 Model Launches with Overwhelming Support:
Garnering excitement for its multilingual capabilities and enhanced benchmarks, the release on platforms like Hugging Face highlights its practical evaluations.
Call for JSON Schema Support in Mozilla AI:
Requests for JSON schema inclusion in the next version to ease application development were prominently noted in community channels.
Keynote on Robotics AI and Foundation Models:
Investment interests in 'ChatGPT for Robotics' amid foundation model companies underscore the strategic alignment detailed in Newcomer's article.
Discussion of Various Topics in Discord Channels
In a series of Discord communities related to AI and technology, discussions cover a wide range of topics and updates. From advancements in AI models like Qwen2 and the challenges of handling messy data in MLOps to the latest news on companies like Cohere and Databricks, community members share insights and engage in technical discussions. Additionally, Discord channels like LangChain AI explore knowledge graph construction security measures, while others like OpenRouter focus on server management tools. These communities provide a platform for AI enthusiasts and engineers to collaborate, seek advice on technical issues, and stay updated on the latest developments in the field.
LLM Finetuning - Jason Improving RAG
Users expressed frustration with the difficulties of extracting data from PDFs, particularly tables and infographics, when using RAG systems. Tools like PyMuPDF, AWS Textract, and converting PDFs to Markdown were suggested as potential solutions, but challenges remained. Markdown tables were noted to be malformed often, impacting the usability of the data extracted. This discussion highlights the ongoing struggle to effectively handle complex data formats within RAG systems.
Optimizing RAG and LLM Finetuning Discussions
The importance of chunking strategies in text data for RAG was highlighted, with recommendations for token numbers and overlap percentages. Fine-tuning embedding models for better RAG performance was emphasized, along with the use of synthetic data. LanceDB was discussed as a database alternative for managing large-scale, multimodal data. Additional links were shared for further reading and tools related to RAG implementations. In the LLM Finetuning discussions, exclusive sneak peeks and anticipation for demos were mentioned, along with scheduling conflicts and alarm setting for talks. Miscommunications were cleared up with empathy, and excitement was expressed about Mistral API. Dependency conflicts in Axolotl installation were addressed, along with recommendations for resolving issues like switching Python versions and recompiling Flash Attention. Discussions on TPU efficiency, FSDP tutorials, and model quantization processes were also highlighted. Links to relevant resources and documentation were shared for further exploration.
LLM Finetuning (Hamel + Dan) Discussions
LLM Finetuning (Hamel + Dan) Discussions
- Python Handles Server-Side Code: Discussion around the server-side code indicates that it’s still managed in Python. Points include scaling in Spaces and handling concurrency with Python.
- Fine-tuning with Modal can be complex but is worth exploring: Users can point to a Hugging Face dataset directly, as suggested by Charles. Adjustments should be made to avoid using Volumes for storing this data.
- Use batch processing for validation: Charles advised writing a custom
batch_generatemethod and using.mapfor processing and generating validation examples. He referenced the 'embedding Wikipedia' example for further guidance. - Exploring Modal for cost-efficiency in app hosting: Alan was advised by Charles on potentially moving the retrieval part of his Streamlit app to Modal or considering moving the entire app there. Concerns about cold starts and cost with a 24/7 deployment were discussed.
- Quick support for script errors: Chaos highlighted an issue with the
vllm_inference.pyscript on GitHub, and Charles quickly responded, hinting at potential problems during the build step or GPU availability. Charles emphasized Modal’s culture of speed in support and communication.
Unsloth AI (Daniel Han) Discussions
- Feature Request for Lora-Adapter File Handling: A user expressed the need for an unsloth lora-adapter file conversion process that doesn't require VRAM. They mentioned struggles with saving a ~7GB adapter for llama-3-70b in the current format.
- Persistent Bug and Faster Inference: A user detailed a bug causing persistent logging but mentioned that once fixed, it might result in slight performance improvements. 'Once it's fixed you might get to claim slightly faster inference, since it won't be printing to console every iteration 😄'.
- Handling CUDA Out of Memory Issues: Another member shared the usage of
torch.cuda.empty_cache()to handle GPU memory issues. Inference using lm_head was consuming more memory than expected, leading to a CUDA out-of-memory error. - Running gguf models: There was a discussion on running gguf models using llama-ccp-python, and the lack of support by transformers for running gguf directly. Another user suggested running gguf binaries directly via llama.cpp.
- RAG System Confusion: There was confusion about Mistral AI offering a RAG system; it was clarified that while Mist
Implementing RAG in Mistral AI
Mistral AI does not offer RAG, but there is documentation available for implementing it. The link provided gives guidance on how to implement Retrieval-augmented generation (RAG), an AI framework that combines the capabilities of LLMs and information retrieval systems. It is useful for answering questions or generating content by leveraging both technologies.
Eleuther Research
Nvidia releases open weights variants: Nvidia has released an open weights version of its models in 8B and 48B variants, available on GitHub. The linked page provides ongoing research on training transformer models at scale.
AI historians use ChatGPT for archival work: Historian Mark Humphries found that AI, particularly GPT models, could significantly aid in transcribing and translating historical documents, ultimately creating a system named HistoryPearl. This system outperformed human graduate students in terms of speed and cost for transcribing documents (The Verge article).
MatMul-free models show promise: A new paper (arXiv) introduces MatMul-free models that maintain strong performance at billion-parameter scales while significantly reducing memory usage during training. These models achieve on-par performance with traditional transformers but with better memory efficiency.
Seq1F1B for efficient long-sequence training: Another paper (arXiv) presents Seq1F1B, a pipeline scheduling method aimed at improving memory efficiency and training throughput for LLMs on long sequences. The method reduces pipeline bubbles and memory footprints, enhancing scalability.
QJL quantization approach for LLMs: The QJL method, detailed in a recent study (arXiv), applies a Johnson-Lindenstrauss transform followed by sign-bit quantization to eliminate memory overheads in storing KV embeddings. This approach significantly compresses the KV cache requirements without compromising performance.
Eleuther, Perplexity AI, and Perplexity AI ▷ Sharing
In the Eleuther channel, discussions involved addressing errors with llama-3, integrating OpenAI's batch API, and aligning brain data with Whisper embeddings. The Perplexity AI channel highlighted new features in Perplexity Pro, issues with reading PDF files, budget constraints for MVP projects, discontinuation of specific labs features, and queries on future app features. Meanwhile, in the Perplexity AI ▷ Sharing channel, various topics were covered such as Bitcoin's history, Perplexity AI's capabilities, accessing paywalled content, Revit 2024 enhancements, and insights on navigator.userAgent outputs. Additionally, discussions in the Cool Links channel delved into KANs vs. MLPs with torch.compile, practical profiling experiences, concerns over operator fusion, and requests for further collaborations. The CUDA MODE channel discussed column-major order in cublas, proposed consolidated memory allocations, improvements in GPU CI checkpointing, and C++ requirements for cublas and cutlass.
Modular (Mojo 🔥)
Members discuss various topics related to Modular (Mojo 🔥) including teaching Python without 'footguns,' storing C function pointers in a Mojo struct, the performance comparison between Mojo and Python, collaboration in community contributions, and optimizing code snippets for aesthetics and performance. The conversations cover aspects like encouraging structured learning, leveraging C functions in Mojo, exploring language performance factors, encouraging community involvement, and seeking advice on code optimization.
Dynamic libpython Update and Cohere Highlights
Jack Clayton highlighted a new feature in the latest nightly that allows dynamic libpython selection, removing the need to set MOJO_PYTHON_LIBRARY. This improvement ensures access to Python modules in the active environment and the folder of the target Mojo file or executable. Cohere has raised $450 million in funding, IBM's Granite models are praised for transparency and enterprise benefits, and Databricks celebrated being named a leader in Forrester’s AI foundation models report. Qwen 2 model is released, beating Llama 3 with a 128K context window, while Browserbase announces a seed funding and Nox launches a new AI assistant. Several tweets and updates are mentioned related to AI discussions and launches. Cohere announced a startup program for early-stage founders and detailed changes to their Chat API effective June 10th, emphasizing multi-step tool use options. Links to relevant articles and resources are provided.
Nous Research AI World-Sim
The section discusses updates made to the WorldSim Console to fix mobile text input bugs and introduce new features like improved commands and the ability to disable visual effects. Specific bug fixes for users were also addressed, including a text duplication glitch and text jumping while typing. The section highlights the enhancements made in the WorldSim Console for a better user experience.
Qwen2 Launch and LangChain AI Discussions
The Qwen2 model launch was announced in the LAION channel, featuring significant enhancements from Qwen1.5. The model supports additional languages, excels in benchmarks, and extends context length. LangChain AI discussions in another channel covered topics such as constructing knowledge graphs, tracking customer token consumption, confusion over tools decorator, creating colorful diagrams for RAG, agent collaboration frameworks, and searching for GUI helper files.
Newsletter and Sponsor
This section includes a link to a newsletter at latent.space and mentions that the content is brought to you by Buttondown, a platform for starting and growing newsletters.
FAQ
Q: What are some highlights of the Qwen2 models mentioned in the essay?
A: The Qwen2 models are highlighted for their multilingual capabilities, enhanced benchmarks, and practical evaluations. They are part of various AI-related developments shared on Discord.
Q: What is Mistral AI's documentation on Retrieval-augmented generation (RAG) about?
A: Mistral AI's documentation on RAG provides guidance on how to implement Retrieval-augmented generation, an AI framework that combines the capabilities of Large Language Models (LLMs) and information retrieval systems to generate content or answer questions.
Q: What are some key features of the Nvidia open weights variants released?
A: Nvidia released open weights versions of its models in 8B and 48B variants. These models are aimed at training transformer models at scale and ongoing research in scaling training processes.
Q: What was highlighted about using ChatGPT models for archival work?
A: Historians found that AI, particularly GPT models like ChatGPT, could significantly aid in transcribing and translating historical documents. This led to the creation of HistoryPearl, a system that outperformed human graduate students in terms of speed and cost for transcribing documents.
Q: What is the QJL quantization approach for LLMs focused on?
A: The QJL method applies a Johnson-Lindenstrauss transform followed by sign-bit quantization to LLMs. This approach aims to eliminate memory overheads in storing key-value (KV) embeddings, significantly compressing KV cache requirements without compromising performance.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!