[AINews] DBRX: Best open model (just not most efficient) • ButtondownTwitterTwitter
Chapters
Reddit and AI Twitter Recap
High Level Discord Discussions
Discord Communities Highlights
Discord Channel Summaries
Exploring AI Models and Benchmarks
Continuation of AI Community Conversations
AI and Technology Development Discussions
Latent Space Updates
HuggingFace Community Discussions
NLP and Image Generation Discussions
Links Mentioned and Discussions
Innovative CUDA Modes and Discussions
Axolotl and DBRX Discussion
LangChain AI Documentation and Community Discussions
Discussions on Various AI Topics
Reddit and AI Twitter Recap
The Reddit section provides insights on AI models, benchmarks, applications, use cases, development, optimization, hardware, infrastructure, news, and discussions. Highlights include Claude 3 Opus in the Chatbot Arena, LocalAI releases, and discussions about AMD GPU usage. On the other hand, the AI Twitter Recap covers model releases, updates, frameworks, tools, research, and techniques in the AI field, such as Claude 3 Opus outcompeting GPT-4 and various tools like Llama Guard and Quanto 0.1.0 being released.
High Level Discord Discussions
The Discord channels Stability.ai, Nous Research AI, Unsloth AI, Perplexity AI, OpenInterpreter, LM Studio, Latent Space, and HuggingFace engage in various discussions around AI models, technology advancements, and community collaborations. Topics include the anticipated release of Stable Diffusion 3.0, challenges with LLMs in context recall tasks, and enhancements in model training methods. Additionally, conversations span from hardware optimizations to AI technology advancements and the use of AI for human cognitive enhancement. The Discord communities showcase a vibrant exchange of ideas, feedback on AI models, and strategies for optimizing performance.
Discord Communities Highlights
The discord communities highlighted in this section cover a range of topics and discussions, showcasing the latest trends and developments in the AI field. From RAFT techniques enhancing Large Language Models (LLMs) to upcoming meetups like the LLMOps Developer Meetup, these communities are abuzz with cutting-edge advancements. Engineers are troubleshooting issues related to AI models, deployment techniques, and integration woes, with a strong emphasis on collaborative problem-solving. The introduction of new models like DBRX and advancements in autoregressive models signal a shift towards more efficient and powerful AI technologies. Additionally, the discussions touch upon philosophical AI, AI ethics, and the potential of multilingual models, reflecting a holistic approach to AI development and innovation.
Discord Channel Summaries
This section covers various discussions and developments in different Discord channels related to AI, models, and tools. From admiration for personal study notes on tinygrad to discussions on DBRX large language model integration, GPU caching recommendations, documentation destiny, and various community interactions and challenges in different Discord channels.
Exploring AI Models and Benchmarks
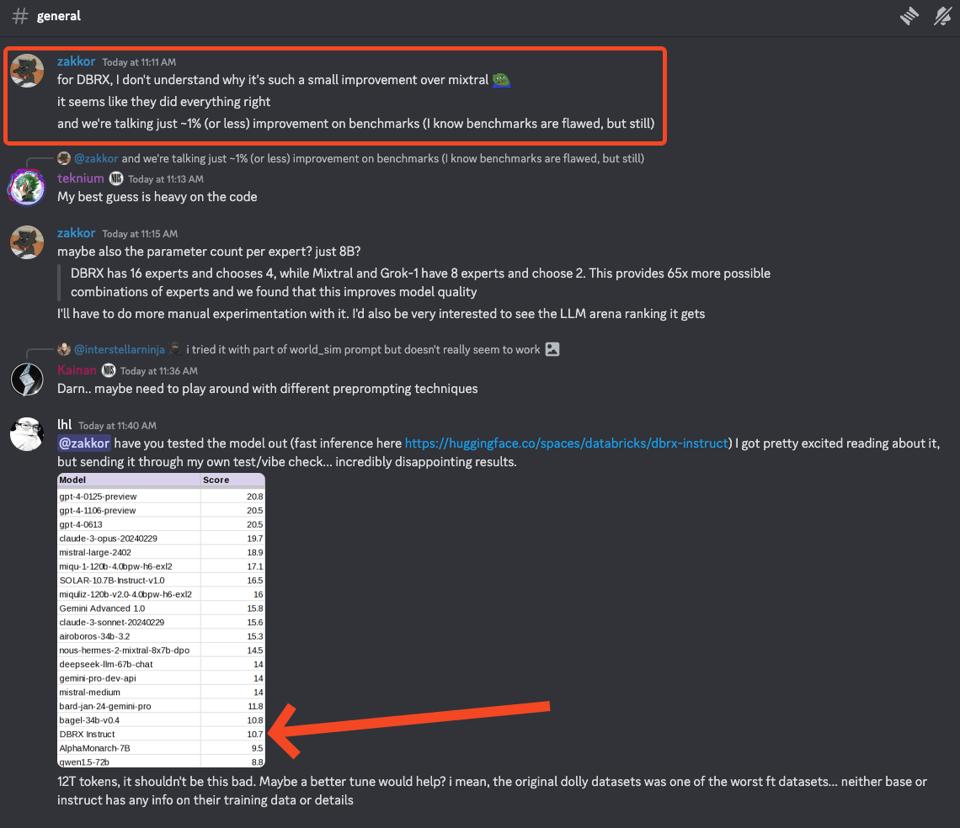
The section discusses various AI models and benchmarks in the AI research community. It includes insights on the disappointing performance of the DBRX model despite its extensive training, debates on the efficiency of MoE models, criticisms of DBRX's system prompt, comparative analysis of open models like Mixtral and DBRX, and discussions on hardware capabilities for large language models. Links to related articles and repositories are also shared for further exploration.
Continuation of AI Community Conversations
Unsloth AI (Daniel Han) ▷ #help
-
Members discussed compatibility questions regarding transferring a LoRA adapter trained on a 4-bit quantized model to other versions.
-
Example shared on continuing pretraining on LLMs with domain-specific data recommended in Unsloth AI.
-
Query on obtaining F1 score values post training and impact of using Trainer vs. SFTTrainer on outcomes.
-
Seeking advice on optimal batch size for fine-tuning Mistral 7b on a 16GB GPU focusing on context length to reduce padding.
-
Confusion discussed on applying chat templates without a pre-downloaded tokenizer and the additional coding effort required.
Unsloth AI (Daniel Han) ▷ #showcase
-
Emphasis on continuous integration, deployment, and evaluation with models gemma2b and tinyllama.
-
Showcase of personal models on a Hugging Face page.
-
Commentary on technical difficulties faced in loading the Hugging Face leaderboard page.
Unsloth AI (Daniel Han) ▷ #suggestions
-
Discussion on exploring LLMs for languages beyond English and technique by Yanolja for expanding LLMs in Korean.
-
Potential of localizing LLMs for Japanese language tasks with resourceful dataset ParallelFiction-Ja_En-100k.
-
Conversation on Layer Replication using LoRA training in Unsloth with members.
-
Sharing compression techniques for efficient model inference through embedding quantization.
-
Paper shared on Layerwise Importance Sampled AdamW (LISA) surpassing LoRA training available on arXiv.
AI and Technology Development Discussions
AI and Technology Development Discussions
- Members discussed the development of AI models like GPT-Investor on GitHub. There were conversations about setting up API base flags, the versatility of OI Interpreter, installation issues on Windows, shipping queries, and the rapid advancement of AI technology. The community also explored open-source libraries like pollen-vision, shared experiences with LM Studio, and discussed hardware issues and optimizations. LM Studio updates, beta releases, and discussions on model capabilities were prominent topics. Additionally, the chat included debates on GPT's prospects, AI assistance in coding, and hypothetical scenarios of AI collaboration and autonomous development.
Latent Space Updates
The section discusses recent updates and developments in the HuggingFace Latent Space community. Topics covered include the ability to create chat assistants using information from websites, new features in Sentence Transformers v2.6.0, admiration for 4D Gaussian splatting technology, updates to various Hugging Face libraries, and clarification on the visuals generated from the 4D Gaussian splatting demo. The community also shared links to demonstrate the mentioned technologies.
HuggingFace Community Discussions
General
- Quest for Learning NLP: Members seek recommendations for learning NLP resources on Hugging Face, including courses on NLP, Deep RL, Audio, and ML for Games.
- Concerns About LLM Download Times: Discussion on a user's experience with slow download times for the Mistral 7B model using LM Studio on Ubuntu 22.04.
- Misleading Model Capabilities: Noted discussion on the capabilities of models like CodeLlama and the importance of relying on documentation rather than model-generated assertions.
- Deciphering LLMs on MacBook GPUs: Insights shared on running large language models like Mistral and Llama on local devices like MacBook with M1 chip.
- TensorRT-LLM vs Other Frameworks for GPU Performance: Comparison of running LLM inference with various frameworks like AWS SageMaker, Runpod, Vast AI, and Kaggle.
Computer Vision
- Seeking Text Error Detection Model: Inquiry about models to detect text errors in images and the need for finetuning if existing models are inadequate.
- Normalization Discrepancy in Medical Imaging: Discussion on varying normalization ranges in CT image preprocessing and the efficacy of nnUNet's normalization strategy.
- Fine-Tuning SAM (Segment Anything Model): User seeks advice on data requirements to finetune SAM and shares relevant links for guidance.
- Using Stitched Images for Model Fine-Tuning: Exploration of using pre-stitched images as training data for model finetuning.
- Challenges with Image Summarization for Technical Drawings: Community advice sought for training a model to recognize patterns in technical drawings and the suggestion to consider the Llava-next model for fine-tuning on a custom instruction dataset.
NLP and Image Generation Discussions
NLP and Image Generation Discussions
- A member in the HuggingFace Discord channel is seeking a comprehensive roadmap for beginning NLP studies in 2024, including subjects, courses, and books to consult.
- Discussions are initiated around the creation and properties of regularization images for training, the announcement of a new speed champion model, sdxs, and a guide on outpainting using ControlNet.
- Members are seeking guidance on generating variations of an existing batch of images and inquiring about modifying images with winter themes.
- In the LlamaIndex Discord channel, discussions include techniques like RAFT for fine-tuning Large Language Models (LLMs) for domain specificity and upcoming developer meetups on LLMOps and advanced RAG techniques.
- A user faces issues concerning RAPTOR PACK, embedding API responses, and conflicts between Langchain and LlamaIndex packages.
- Discussions include strategies for chunking PDFs for embeddings and queries about IngestionPipeline.
- The Centre for GenAIOps is introduced by the National Technology Officer (NTO) and the Chief Technology Officer (CTO) to address constraints in building GenAI-powered apps.
- OpenAI discussions involve recognition of Sora's creative influence, user requests for an undo feature in chatbot conversations, and inquiry on LLM hardware requirements for a 60b parameter AI chatbot.
Links Mentioned and Discussions
- Links mentioned: In this section, various links are provided related to the discussions on AI models, techniques, and industry collaborations.
- OpenAI Discussions: Different discussions are held regarding training AI for Apple ecosystem expertise, API integration troubleshooting, differences in assistant API responses, becoming an Apple Certified Support Professional through AI, and expanding AI access. Valuable insights and suggestions are shared among the community.
- Prompt Engineering Discussions: Conversations revolve around GPT memory limitations in PDF extraction, understanding the context window, suggestions for handling PDF control enhancements, improving code generation prompts, and stopping ChatGPT stub code responses. Members discuss challenges, solutions, and tips related to prompt engineering.
- API Discussions: Members talk about prompt engineering for specific PDF extraction, unraveling the mysteries of context windows, improving model efficiency with embeddings, automating information extraction from PDFs, and ensuring complete code outputs from ChatGPT. Different strategies and techniques are shared to enhance the efficiency and accuracy of models.
- Research Discussions: Discussions vary from examining autoregressive model evaluation on Squad, exploring Squad evaluation alternatives, introducing RAFT technique, assessing the impact of multilingual tokens, and advocating for open weights legal status. Members delve into evaluating different models, techniques, and the implications of industry practices.
- Scaling Laws Discussions: Members engage in discussions around muP utilization, normalization technique debates, GPT-4 references, Grok-1 model's utilization of muP, and upcoming insights on muP. Various perspectives and experiences are shared regarding tuning hyperparameters and utilizing different techniques.
- General Discussions: Topics covered include concerns over AI model output, model training challenges, job opportunities at fast inference startups, satirical takes on AI claims, and debunking misleading visual data representation. Members express concerns, share job opportunities, and analyze different aspects of AI model behaviors and industry trends.
Innovative CUDA Modes and Discussions
This section covers various topics related to CUDA modes and insightful discussions within different channels on Discord. It includes information on innovative advancements like Layer-Pruning LLMs, B-LoRA's image decomposition method, and automation in image captioning. Additionally, discussions on challenges and solutions with CUDA, PyTorch data type pitfalls, and advancements in Triton and Ring Attention models are highlighted. These conversations provide valuable insights into cutting-edge developments and problem-solving strategies within the CUDA community.
Axolotl and DBRX Discussion
The discussions in the Axolotl community highlight various topics related to new AI models and tools. Members discuss the effectiveness of models like Haiku and Starling-LM 7B, as well as the technical hurdles faced in utilizing large language models (LLMs) like DBRX. Issues regarding hardware limitations, model training woes, and compatibility with certain versions of transformers or PyTorch binary models are also raised. The conversations shed light on the community's interest in the development and practical implementation of cutting-edge LLMs. Additionally, the deployment of DBRX Base, a mixture-of-experts architecture, garners attention and sparks discussions about its potential capabilities and training data. On the Axolotl Dev channel, troubleshooting tips for opening Jupyter notebooks and bug fixes in Trainer.py are shared, reflecting the community's collaborative effort in addressing technical challenges. Overall, the discussions in the Axolotl community showcase a mix of excitement, shared knowledge, and practical problem-solving in the realm of AI model development and utilization.
LangChain AI Documentation and Community Discussions
The section discusses issues such as inconsistencies in LangChain documentation and concerns about specific methods. It also covers community interactions related to LangChain on platforms like Discord. This includes a member encountering errors while using LangChain in chat mode, seeking technical assistance, and some users introducing new projects like the Index Network. Additionally, there are announcements of tutorials on YouTube related to LangChain applications, as well as the launch of GoatStack AI, an AI-powered research assistant. The section concludes with discussions on Tinygrad, DBRX, and Mistral CEO within the community, including technical insights, license limitations, and humorous exchanges.
Discussions on Various AI Topics
This section delves into diverse discussions within AI-related communities. It covers topics such as industry datasets raising the standards, the prominence of GPT-4, using AI2 credit card for experiments, introducing a Discord bot named Sora, the release of DBRX Instruct model by Databricks, queries on LLM training and language-specific prompts, the dilemma of dataset size adequacy, and more. Each subtopic presents insights, queries, and updates from different Discord channels related to AI research and development.
FAQ
Q: What are some highlights from the Reddit section related to AI?
A: The Reddit section provides insights on AI models, benchmarks, applications, use cases, development, optimization, hardware, infrastructure, news, and discussions.
Q: What are some discussions covered in the AI Twitter Recap?
A: The AI Twitter Recap covers model releases, updates, frameworks, tools, research, and techniques in the AI field.
Q: What are some topics discussed in the Discord channels Stability.ai, Nous Research AI, and other AI-related channels?
A: Discussions cover various topics like AI models, technology advancements, community collaborations, challenges with LLMs, hardware optimizations, AI technology advancements, and the use of AI for human cognitive enhancement.
Q: What specific discussions have taken place in the Unsloth AI Discord channel?
A: Discussions include topics like transferring a LoRA adapter trained on a 4-bit quantized model, pretraining on LLMs with domain-specific data, F1 score values post training, optimal batch size for fine-tuning Mistral 7b, and applying chat templates without a pre-downloaded tokenizer.
Q: What are some general AI and technology development discussions that have been happening?
A: Discussions cover the development of AI models like GPT-Investor on GitHub, API base flags, OI Interpreter versatility, hardware optimizations, LM Studio updates, debates on GPT's prospects, AI assistance in coding, and hypothetical scenarios of AI collaboration.
Q: What topics have been covered in the HuggingFace Latent Space community?
A: Topics covered include creating chat assistants using website information, new features in Sentence Transformers v2.6.0, 4D Gaussian splatting technology, updates to Hugging Face libraries, and clarification on visuals generated from 4D Gaussian splatting demo.
Q: What are some specific discussions happening in the field of Computer Vision?
A: Discussions include seeking text error detection models, normalization discrepancies in medical imaging, fine-tuning SAM (Segment Anything Model), using stitched images for model fine-tuning, and challenges with image summarization for technical drawings.
Q: What have been the discussions around NLP and image generation in various Discord channels?
A: Discussions include seeking NLP study resources, regularization images for training, new speed champion model announcements, outpainting using ControlNet, RAFT technique discussions for LLM fine-tuning, and upcoming developer meetups on LLMOps and RAG techniques.
Q: What valuable insights have been shared in the discussions around Prompt Engineering and API in different Discord channels?
A: Insights include discussions on GPT memory limitations, context windows, improving model efficiency with embeddings, automating information extraction from PDFs, and ensuring complete code outputs from ChatGPT.
Q: What discussions have taken place in the Axolotl community related to new AI models and tools?
A: Discussions cover the effectiveness of models like Haiku and Starling-LM 7B, issues with DBRX utilization, hardware limitations, model training woes, compatibility with versions of transformers or PyTorch binary models, and deployment of DBRX Base.
Q: What are some key points discussed within the CUDA community?
A: Discussions include advancements like Layer-Pruning LLMs, B-LoRA's image decomposition method, automation in image captioning, challenges and solutions with CUDA, PyTorch data type pitfalls, and advancements in Triton and Ring Attention models.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!