[AINews] Anthropic's "LLM Genome Project": learning & clamping 34m features on Claude Sonnet • ButtondownTwitterTwitter
Chapters
Anthropic's "LLM Genome Project"
AI Reddit, Discord, and Twitter Recaps
Discord Community Highlights
Interconnects (Nathan Lambert) Discord
Discord Guilds Updates
LLM Finetuning Updates
LLM Finetuning (Hamel + Dan) ▷ #jason_improving_rag
HuggingFace Cool Finds
HuggingFace ▷ #i-made-this
LM Studio Models Discussion Chat
LM Studio Announcements
Modular Mojo Performance and Benchmarks
Discussion on Recent AI Developments
Nous Research AI - Project Obsidian
OpenRouter (Alex Atallah) General
Handling Advanced Model Fine-Tuning and Memory Optimization
OpenInterpreter Discussions
Anthropic's "LLM Genome Project"
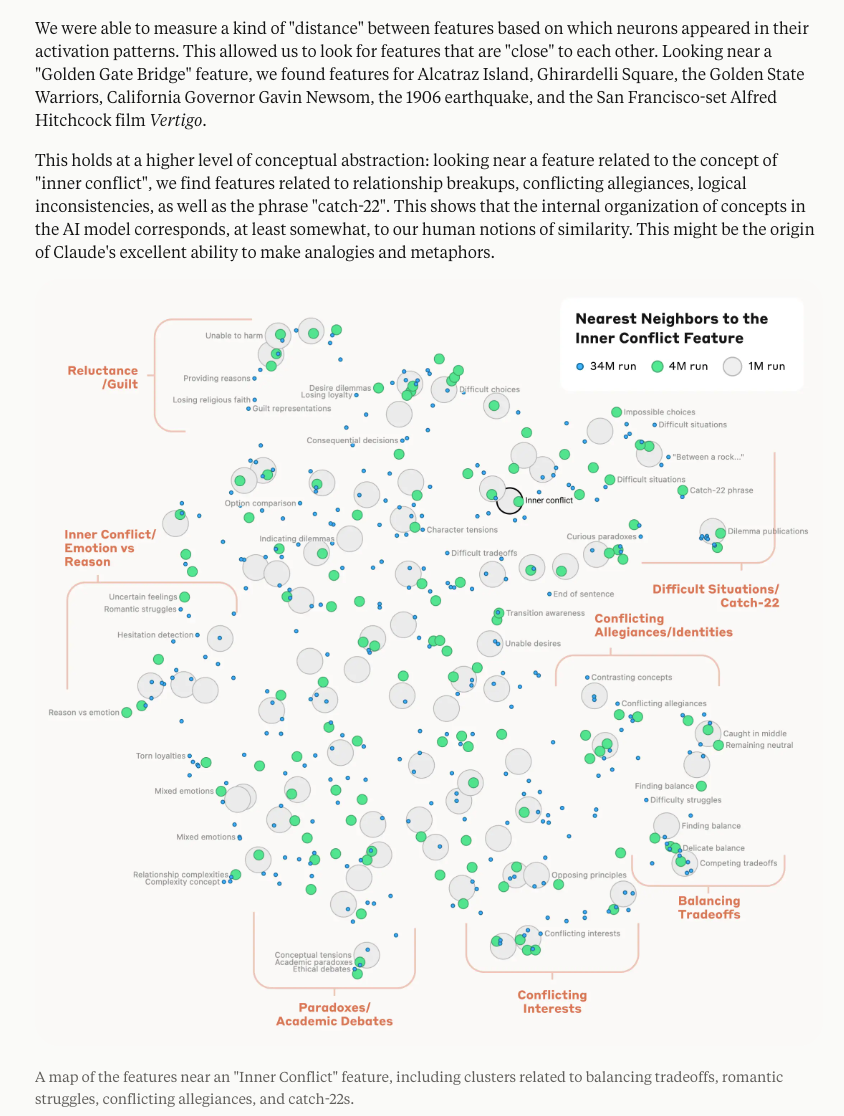
The article discusses Anthropic's "LLM Genome Project," which focuses on Scaling Monosemanticity in their modern MechInterp trilogy. The project scales up to 34 million features on the Claude 3 Sonnet model, enabling interpretability magic. Instead of the concept of "superposition," Anthropic introduces the analogy of "dictionary learning," which isolates patterns of neuron activations that recur across different contexts. The article explores the various abstract features encoded in the 34 million features, including code features and errors. Anthropic demonstrates intentional modifiability by clamping features, showcasing the model's interpretability. The article also highlights the reactions from prominent individuals in the AI field and provides a Table of Contents for detailed summaries of the AI discussions on Twitter, Reddit, and Discord channels.
AI Reddit, Discord, and Twitter Recaps
This section covers a recap of AI-related content shared on Reddit, Discord, and Twitter. It includes discussions on OpenAI controversies, demonstrations of Copilot and GPT-4o capabilities, advancements in AI models and initiatives like Scale AI, and humorous memes related to AI developments. The content delves into legal issues, technical advancements, community collaborations, and the path towards AGI, providing a comprehensive overview of recent AI-related discussions across various platforms.
Discord Community Highlights
The various Discord communities have been buzzing with discussions and activities related to AI technologies. From updates on various models like Phi-3 and CogVLM2 to technical support and research initiatives, the communities have been actively engaged. Discussions ranged from model integration tactics to challenges in hardware performance, from the inventive use of APIs to the controversial aspects of AI ethics and legality. Members shared insights on system setups, new tools, and potential future developments, showcasing a dynamic and collaborative environment within the AI community.
Interconnects (Nathan Lambert) Discord
Ethical Concerns in AI
- OpenAI halts use of "Sky," a voice AI resembling Scarlett Johansson, due to legal pressure and negative public perception. This incident sparks discussions on the ethical concerns of voice mimicry and consent.
- Anthropic ramps up compute resources, stirring community interest in potential developments.
AI Model Evaluations
- LMsysorg introduces "Hard Prompts" category, challenging AI models like Llama-3-8B. The rigorous evaluation questions the effectiveness of current judge models.
- OpenAI faces scrutiny over allegations of reneging on a 20% computing power commitment for their Superalignment team.
Quirks and Legal Considerations
- Nathan Lambert's domain purchase and banter about using AI datasets sheds light on the quirky side of AI development.
- Discussions on balancing local processing versus cloud-dependent safety verifications for Microsoft Surface AI hint at potential optimizations.
Discord Guilds Updates
The section highlights updates from various Discord guilds related to AI and technology. It includes details on the aspirations of sqlite-vec extension, collaboration opportunities, community excitement over sqlite-vec integration with Llamafile, performance advancements in GPT-4o, calls for collaboration from Manifold Research Group and NEKO Project, and discussions on LLM fine-tuning, human-AI collaboration in workshops, and emerging AI use cases. The section showcases a range of activities and initiatives within different guilds, emphasizing collaboration, innovation, and community engagement.
LLM Finetuning Updates
LLM Finetuning (Hamel + Dan) updates were shared in several channels within the Discord community. Modal Credits and Cost Management: Members were guided on obtaining Modal credits and managing service costs efficiently. Fine-Tuning and Model Serving: Recommendations were provided for fine-tuning and serving LLM models on Modal effectively. Modal Support and Tips: Discussions included valuable operational tips, usage of Modal services, and links to relevant GitHub projects. Hybrid Sharding Strategy: Enthusiasm was expressed for the hybrid sharding strategy involving FSDP and DS techniques. Course Enrollment and Usage: New course members, queries about free credits, and discussions on course structures and technical aspects were highlighted. Debate on Discord Features: Members engaged in a debate on Discord stages, course sessions, technical discussions, and introduced resources shared for further reading.
LLM Finetuning (Hamel + Dan) ▷ #jason_improving_rag
- Jason's W&B course wows: A user expressed excitement about Jason's session and mentioned being halfway through his Weights & Biases (W&B) course. They used the teacher emoji to show their admiration.
- Prompt engineering curiosity peaks: Another user inquired about Jason's systematic approach to prompt engineering, praising his extensive work on optimizing prompts. They were eager to learn his 'recipe' during his workshop session.
HuggingFace Cool Finds
Merve showcases PaliGemma's document models:
- Merve shared details on PaliGemma's document understanding capabilities, sparking a discussion.
DeepSpeech inquiry:
- A member inquired about experiences working with Mozilla's DeepSpeech model.
HuggingFace ▷ #i-made-this
Announcing Sdxl Flash Mini:
A member announced the release of SDXL Flash Mini in collaboration with Project Fluently. The model is described to be fast and efficient, with less resource consumption while maintaining respectable quality levels SDXL Flash Mini.
SDXL Flash Demo by KingNish:
Exciting new demo of SDXL Flash available on Hugging Face Spaces, demonstrated by KingNish. This provides a practical showcase of its capabilities SDXL Flash Demo.
Tokun Tokenizer Release:
Inspired by Andrej Karpathy, a member developed a new tokenizer called Tokun, aimed at significantly reducing model size while enhancing capabilities. Shared both the GitHub project and article about testing.
Transformers Library Contribution:
A member celebrated their PR merge into the Transformers library, which fixes an issue with finetuned AI models and custom pipelines. Shared the link for the PR here.
llama-cpp-agent Using ZeroGPU:
The member shared the creation of llama-cpp-agent on Hugging Face Spaces utilizing ZeroGPU technology, indicating a promising advancement in computational efficiency llama-cpp-agent.
LM Studio Models Discussion Chat
- Successful model setup requires right prompts: A member asked how to use the MPT-7b-WizardLM model on LMStudio, and another advised using the correct quantization level and template, pointing to model-specific details on Hugging Face.
LM Studio Announcements
Users discussed the integration of Hugging Face models into LM Studio, along with customization options for model downloads. Limitations on model compatibility were highlighted, mentioning support for GGUF models only. Additionally, users shared tips on improving LM Studio performance, such as adjusting RAM speed impact on models and experimenting with different models. There were discussions on running LM Studio with dual GPUs, seeking models to impose response limits, and addressing null max_tokens issues in Autogen Studio. The section also covered a call for Linux users with AMD GPUs to test LM Studio, experiences with unsupported GPUs on ROCm, and discussions on CPU usage and Linux distributions. Lastly, users praised Arch Linux compatibility with ROCm and debated asynchronous programming methods in Mojo.
Modular Mojo Performance and Benchmarks
Optimizing SIMD Gather and Scatter in Mojo:
A member questioned Mojo's SIMD gather and scatter operations' optimization level, suggesting aligning values to 32-bit boundaries for potential speed improvements. Another member shared their experience, mentioning well-optimized gather and scatter operations, with uncertainty regarding alignment benefits.
Challenges with ARM SVE and SIMD Width:
Discussion highlighted ARM Scalable Vector Extension (SVE) complexities, variable vector widths, and speculative loads challenges across page boundaries. A member noted LLVM struggles with SVE formats due to limited CPU availability.
Consider Reducing SIMD Operations:
A member recommended minimizing gather/scatter operations by always using the highest SIMD width feasible, involving more index manipulation for enhanced performance. They plan to update and share results from their MoCodes project accordingly.
Sorting for Scattered Memory Access:
Another member suggested sorting an array of pointers to optimize performance when handling several kilobytes of scattered memory, especially for iterative decoders.
Vectorized DTypePointer Memset Implementation:
A member shared that a vectorized memset implementation for 100,000 bytes performs 20% quicker than LLVM's call, but this advantage flips for 1,000,000 bytes, expressing concerns about reliability due to 'clobber memory.'
Discussion on Recent AI Developments
Discussion on OpenAI Staff Movement and AISI Hiring
- Speculation on former OpenAI aligners joining the new AISI and criteria for employment.
Evaluation of Dropout in Language Models
- Debate on the relevance of using dropout in modern language models and alternative strategies like label smoothing.
PSA on California SB 1047 Impact on AI Development
- Call to oppose California’s SB 1047 and its potential impact on open-source AI development.
Tool and Technique Sharing for AI Model Development
- Sharing of resources and insights on tools like Flash Attention implementation in JAX and related performance benchmarks.
Nous Research AI - Project Obsidian
Phi-3 Vision unveiled:
A member shared that Phi-3 Vision is now available, describing it as a lightweight, state-of-the-art open multimodal model with 128K token context length. It focuses on high-quality, reasoning dense data from both text and vision sources and uses supervised fine-tuning and direct preference optimization for enhanced instruction adherence and safety.
Explore Phi-3 Vision resources: Key resources include the Phi-3 Microsoft Blog, the Phi-3 Technical Report, and the Phi-3 Cookbook. There is also a link to Phi-3 on Azure AI Studio for practical implementation.
Link mentioned: microsoft/Phi-3-vision-128k-instruct · Hugging Face: no description found
OpenRouter (Alex Atallah) General
GPT-32k faces issues with rate limits:
Users reported encountering token rate limit issues with Azure's GPT-32k model. One user stated, 'Requests to the ChatCompletions_Create Operation under Azure OpenAI API version 2023-07-01-preview have exceeded the token rate limit.'
Phi-3 models discussed for robust performance:
Members discussed Phi-3-medium-4k-instruct and Phi-3-vision-128k-instruct for high-quality, reasoning-dense data handling. Both models incorporate supervised fine-tuning and direct preference optimization for enhanced performance.
New interaction methods with LLMs:
One user shared a thread on a new way of interacting with LLMs using 'Action Commands.' They sought feedback from others to see if anyone had similar experiences.
Handling verbosity in models:
Members discussed handling verbosity in models like Wizard8x22. One suggested lowering the repetition penalty to reduce verbosity, while another noted that different models might be better suited for specific tasks.
Discount request and credit issues for non-profits:
A user had issues with Error 400 related to billing address and requested discounts for non-profits. An admin explained that OpenRouter passes bulk discounts down to users and keeps a 20% margin.
Handling Advanced Model Fine-Tuning and Memory Optimization
In this section, members of the OpenAccess AI Collective discuss issues related to fine-tuning Mistral 7B models, full finetuning vs. LoRA usage for memory retention, and inference configuration problems. They also share insights into memory optimization strategies like increasing gradient accumulation steps, using mixed precision training, and DeepSpeed ZeRO optimization. Additionally, discussions cover the challenges of running gguf format models with LlamaIndex and strategies to adjust settings for more efficient AI Town conversations. Lastly, topics include securing LLM responses for sensitive data and transitioning legacy LangChain agents to LangGraph for improved performance.
OpenInterpreter Discussions
OpenInterpreter Discussions
- OS1 Reference in 'Her' movie sparks realization: Members discuss the connection between 'O1' in Open Interpreter and 'OS1' in the movie 'Her', sparking curiosity among users.
- Seeking help for DevOps AI module: A junior full-stack DevOps engineer seeks assistance in building a lite O1 AI for DevOps tools via discreet earphones.
- Installation and development setup queries: Members discuss project structures and more efficient development setups in Open Interpreter.
- Daily uses and problem-solving with Open Interpreter: Users share use cases, including referencing between devices and summarizing research papers.
- Integrating Text-to-Speech with Open Interpreter: Discussion on combining Text-to-Speech engine with Open Interpreter and relevant GitHub repository.
FAQ
Q: What is the focus of Anthropic's LLM Genome Project?
A: The focus of Anthropic's LLM Genome Project is Scaling Monosemanticity in their modern MechInterp trilogy by scaling up to 34 million features on the Claude 3 Sonnet model.
Q: What analogy does Anthropic introduce instead of the concept of 'superposition'?
A: Anthropic introduces the analogy of 'dictionary learning,' which isolates patterns of neuron activations that recur across different contexts.
Q: What are some of the abstract features encoded in the 34 million features of Anthropic's project?
A: The abstract features encoded in the 34 million features include code features and errors.
Q: How does Anthropic demonstrate intentional modifiability in their model?
A: Anthropic demonstrates intentional modifiability by clamping features, showcasing the model's interpretability.
Q: What were some of the ethical concerns discussed in the AI community?
A: Some of the ethical concerns discussed in the AI community included OpenAI halting the use of 'Sky,' a voice AI resembling Scarlett Johansson, due to legal pressure and negative public perception.
Q: What were some of the challenges faced by OpenAI in relation to their computing power commitment?
A: OpenAI faced scrutiny over allegations of reneging on a 20% computing power commitment for their Superalignment team.
Q: What updates were shared regarding the Phi-3 Vision?
A: Phi-3 Vision was unveiled as a lightweight, state-of-the-art open multimodal model with 128K token context length, focusing on high-quality, reasoning-dense data from text and vision sources.
Q: What issues were reported with Azure's GPT-32k model?
A: Users reported encountering token rate limit issues with Azure's GPT-32k model, where requests to the ChatCompletions_Create Operation exceeded the token rate limit.
Q: What new interaction methods were discussed with LLMs in the community?
A: Discussions included a thread on a new way of interacting with LLMs using 'Action Commands,' seeking feedback from others with similar experiences.
Q: What were some of the considerations regarding verbosity in models like Wizard8x22?
A: Suggestions included lowering the repetition penalty to reduce verbosity in models like Wizard8x22, and noting that different models might be better suited for specific tasks.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!