[AINews] Anime pfp anon eclipses $10k A::B prompting challenge • ButtondownTwitterTwitter
Chapters
AI Recap
High-Level Discord Summaries
Community Discussions on Different Discord Channels
Discord Server Discussions
API vs Web App Model Differences
Shared Insights and Discussions on Various AI Topics
Aurora-M Development and Impact
LM Studio Discussion Highlights
Discord Channel Updates
Exploring Specific AI Model Training and Data Extraction Techniques
Mojo Community Projects
Link Discussion and Model Comparison
LangChain AI Discussion
AI-Related Discussions on AI GPT Models
Expanded Tweets and Discussions on AI Engineering and Knowledge Tools
Discussion on Open Model Weights and AI Regulation
Models and Optimizations Discussions in CUDA Mode
AI Research and Development Discussions
Skunkworks AI Innovations
AI Recap
AI Recap
The AI recap section provides updates on AI-related developments and discussions gathered from various sources like Reddit, Twitter, and Discord. The content covers a wide range of topics including technical developments, research updates, prompting techniques, and discussions on AI agents and robotics. Memes and humorous posts related to the AI field are also highlighted. The section includes summaries from AI Reddit, AI Twitter, and AI Discord platforms, offering insights into recent advancements, research breakthroughs, and lively discussions within the AI community.
High-Level Discord Summaries
Rorschach Test for AI Vision Models
The LLaVA vision-language model underwent a novel 'Rorschach test' by feeding it random image embeddings and analyzing the interpretations, described in a blog post. Moreover, a compact nanoLLaVA model suitable for edge devices was introduced on Hugging Face.
Claude's Memory Mechanism in Question
Technical discussions ensued on whether Claude retains information across sessions or if the semblance of memory is due to probabilistic modeling. Engineers debated the effectiveness of current models against the challenge of persistent context.
Worldsim Woes and Wisdom
Post-DDoS attack, proposals for a Worldsim login system to thwart future threats and discussions of a 'pro' version to include more scenarios were afoot. Meanwhile, philosophical musings floated around potential AI-driven simulations akin to observed realities.
Chunking for RAG Diversity
Suggestions arose to pre-generate diverse datasets for RAG using a chunking script, alongside talk of creating complex multi-domain queries using Claude Opus. Ethical queries surfaced regarding data provenance, specifically using leaked documents from ransomware attacks, contrasting with the clustering strategies like RAPTOR for dataset curation.
The Coalescence of GitHub and Hermes
A GitHub repository, VikParuchuri/marker, was spotlighted for its high-accuracy PDF-to-markdown conversion and can be found on GitHub - VikParuchuri/marker. Discussions focused on enhancing Hermes-2-Pro-Mistral-7B to execute functions with tools configurations, a hurdle matching the challenges delegates face with full-parameter fine-tuning vis-à-vis adapter training in various LLM contexts.
Canada's AI Ambitions and Enterprise LLMs
From the introduction of Command R+, a scalable LLM by Cohere for businesses, to insights into Canada's strategy to champion global AI leadership, the discourse expanded towards understanding SSL certifications, creating local solutions akin to Google Image Search and untangling the surfeit of AI research and synthesis.
Community Discussions on Different Discord Channels
The recent conversations on various Discord channels cover a range of topics within the AI community. The discussions include issues with tooling and optimization strategies, the emphasis on reproducibility and reliable documentation, as well as the use of AI in different applications such as code generation and content creation. Additionally, there are insights shared on hardware advancements, AI ethics, and the challenges faced in fine-tuning models. Overall, these exchanges reflect a vibrant and engaged community seeking to enhance AI practices and applications.
Discord Server Discussions
Tinygrad (George Hotz) Discord:
- Tinygrad Takes a Step Back: George Hotz reverts the command queue in tinygrad and integrates the memory scheduler directly with the current scheduler model.
- TinyJIT Under the Microscope: Inaccuracies found in the TinyJit tutorial, encouraging users to submit pull requests for corrections.
- Tinygrad Learning Expanded: Tutorials and guides available for contributing to tinygrad, focusing on topics like multi-GPU training.
- Discord Roles Reflect Contribution: George Hotz redesigns roles within the tinygrad Discord to reflect community engagement and contribution levels.
- Unpacking MEC's Firmware Mystery: Discussions about MEC firmware's opcode architectures, including speculation on RISC-V.
Mozilla AI Discord:
- Scan Reveals Llamafile's Wrongful Accusation: Versions of llamafile identified as malware, users enabled to resolve issues running llamafile on Kaggle.
- RAG-LLM Gets Local Legs: Local distribution of RAG-LLM application without Docker or Python feasible through llamafile.
- Taming the Memory Beast with an Argument: Out of memory errors rectified by adjusting parameters based on GPU capabilities.
- Vulkan Integration Spurs Performance Gains: Proposal to integrate Vulkan support in llamafile for performance enhancements.
DiscoResearch Discord:
- No Schedules Needed for New Optimizers: Meta's schedule-free optimizers introduced for AdamW and SGD in huggingface/transformers repository.
- AI Devs Convene in Hürth: AI community event focusing on synthetic data generation and LLM/RAG pipelines scheduled in Germany.
- Sharing Synthetic Data Insights Sought: Demand for knowledge on synthetic data strategies high, emphasizing German translated versus generated data.
- Command-R Tackles Tough Translations: Command-R model excels at translating archaic Middle High German text, underscoring potential in historical language processing.
- Open-Source Model Development Desired: Anticipation for open-source release of Command-R.
AI21 Labs (Jamba) Discord:
- Slow and Steady Wins the Race?: Comparison between Jamba's Mamba model and a standard Transformer model in training speed.
- Size Doesn't Always Matter: Introduction of scaled-down Jamba models achieving decent performance.
- Weights and Measures: Creator's application of Slerp for weight reduction in Jamba models sparks interest.
- Power Play: Efficient GPU utilization sought for handling a 52B Jamba model.
- What's the Best Model Serving Approach?: Conversations around effective inference engines for Jamba models.
Datasette - LLM (@SimonW) Discord:
- QNAP NAS - A Home Lab for AI Enthusiasts: Setting up a QNAP NAS as an AI testing platform.
- Streamlining AI with Preset Prompts: Curiosity about storing and reusing system prompts in AI interactions.
- Alter: The Mac's AI Writing Assistant: Alter launching in beta, offering AI-powered text improvement services to macOS users.
- A Singular AI Solution for Mac Enthusiasts: Alter app aims to provide context-aware AI features across all macOS applications.
Skunkworks AI Discord:
- Dynamic Compute Allocation Sparks Ideas: Discussions on dynamic allocation of compute resources within neural networks.
- Rethinking Training Approaches for neurallambda: Exploratory talks on improving training efficacy.
- Innovative Input Handling on the Horizon: Consideration of novel input approaches for neurallambda.
- Improving LLMs Data Structuring Capabilities: Instructional videos shared on generating structure from LLMs.
- Video Learning Opportunities: Educational video resources provided for self-guided learning.
API vs Web App Model Differences
- Discussions revealed differences between results from the API and the web application, with concerns about result quality and hallucinations present.
- Users suggest that using the 'sonar-medium-online' model via the API should yield similar results as the 'Sonar' model on the web version without Pro.
- Inquiries were made about the accessibility of the model used in pplx-pro via the API, clarifying that Pro search is only available on the web and their apps, not through the API.
Shared Insights and Discussions on Various AI Topics
In this chunk, members discuss advice for switching between different UIs, particularly from Automatic 1.1.1.1 to StableSwarm for a better user experience. Furthermore, conversations revolve around challenges related to model limitations, including issues with server crashes and model saving. The group also examines the curiosity about LLM vision model alternatives and strategies for better LLM training to avoid GPU overheating. Lastly, there is anticipation for Unsloth AI's upcoming features and discussions on gradient checkpointing and model merging.
Aurora-M Development and Impact
Introducing Aurora-M: A new 15.5 billion parameter open-source multilingual language model named Aurora-M has been developed, following the U.S. Executive Order on AI. It demonstrates cross-lingual impact of mono-lingual safety alignment and surpasses 2 trillion training tokens. Cross-Lingual Safety Impact Validated: Safety alignment tuning on English enhances safety in multiple languages, such as German, showcasing the cross-lingual impact of mono-lingual safety alignment. Peer Recognition: The community supports the Aurora-M project, acknowledging its innovation with positive reactions like 'great work! 🔥'. Aurora-M's Upcoming Developments: The project plans to enhance Aurora-M by training a mixture of experts using LoRA and a subsequent merge. Feedback from the Unsloth AI community is welcomed, particularly regarding the use of LoRA fine-tuning notebooks.
LM Studio Discussion Highlights
Praise for LM Studio:
Members found LM Studio to outperform other local LLM GUIs like oogabooga and Faraday, appreciating the quality results even using the same models and instructions.
Feature Expansion Request:
A suggestion to add file reading support and various modes such as text to images, image to text, and text to voice functionalities for LM Studio was proposed, seeking improvements similar to an existing tool named Devin.
Vision Models Awestruck:
Members are excited by the vision models tested, thanking LM Studio for its utility. Vision models are available on Hugging Face.
Troubleshooting Download Issues:
There were issues downloading the Linux beta version of LM Studio with a user trying on Pop!_OS 22.04 LTS. The issue was identified as a bug on the website, with a direct link to the AppImage being provided.
Supporting the Uncensored Model:
A request was made for LM Studio to support a new, uncensored model named Dolphin 2.8 Mistral 7b v0.2, which is available on Hugging Face.
Discord Channel Updates
- In the 'today-im-learning' channel, members are discussing knowledge graphs and a new learning platform, Collate.
- The 'cool-finds' channel highlights recent advancements in AI research, including PIDNet, MoD proposal, and multi-document solutions.
- The 'i-made-this' channel showcases neuro-symbolic AGI, paper replication repository, Gradio for audio datasets, RNN for MNIST, and 'Where's My Pic?' project.
- The 'reading-group' channel covers discussions on paper reading events, learning resources, model exploration guidance, and repository for session recordings.
- The 'computer-vision' channel talks about HuggingFace model repositories, monitoring GPU usage, manipulating parquet files, and seeking resources for diffusion models in video quality.
Exploring Specific AI Model Training and Data Extraction Techniques
- Training XCLIP with More Frames: Experience shared on pretraining an XCLIP model with extended frame capacities, facing challenges with losses and NaNs.
- Fine-tuning Mistral7b for Specific Data Extraction: Query about fine-tuning Mistral7b for JSON data extraction, contemplating the need for a more specialized model.
- Parsing Tweets Without Twitter API: Seeking alternatives to scrape tweets without the Twitter API for a simpler solution.
- Colab Pro+ struggles with WizardLM models: Participant facing memory errors with WizardLM-13B and WizardLM-7B models on Google Colab Pro+ despite using different GPUs.
- 10M Context Window Feasibility in Gemini 1.5: Discussion sparked by Gemini 1.5 paper's 10M context window claim, with a member inquiring about the method for substantial attention matrix calculation.
- Imputing Null Values with LLM: Need expressed to impute null values in a dataset with LLM based on context, seeking references or assistance for guidance.
Mojo Community Projects
Special Functions Now in Mojo
An update to the Specials package introduces several elementary mathematical functions such as exp, exp2, expm1, log, and log1p. These implementations prioritize numerical accuracy over FLOPS, and benchmarks can be found in the package repository.
SICP Gets Mojofied
The classic textbook 'Structure and Interpretation of Computer Programs' is being ported to Mojo language in the sicp_mojo project, currently referencing the JavaScript version.
Mojo Algorithms Collective Initiative
A member is planning to rewrite popular algorithms in Mojo, such as Dijkstra's and different sorting methods, and is interested in coordinated efforts.
One-stop Mojo Packages Repo
Community members can share their Mojo packages through PRs in the mojo-packages repository, which aims to function as a central hub until an official package manager is available.
Mambamojo Collaborative Project
A GitHub repository called mamba.mojo is seeking collaborators to work on implementing Mamba in pure Mojo, from models to inference and training.
Link Discussion and Model Comparison
The web page contains discussions surrounding various links and model comparisons. In the eleuther section, there are discussions about the NSF Reviewer pointing out the low number of stars for the nnsight project and some technical conversations regarding GPU utilization, bigbench task recognition, CLI command errors, logit bias for MCQA tasks, and temperature settings affecting output quality. OpenAI discussions highlight topics like sentiment analysis for recordings, anticipation for GPT-5, community support, and questions about AI training data sources. In the OpenRouter section, announcements are made regarding updates on Claude 3 modality, messaging enhancements, and prompt template improvements for DBRX. The API-discussions section delves into the emulation of human consciousness by AI, GPT depictions, Dall-E usage for dissertation design, refining GPT prompts, and discussions about ChatGPT's system prompts and tools. Lastly, general discussions cover topics such as API frontends for OpenRouter, favorite models for roleplay and coding, model performance comparisons, exploration of model features, and concerns over model rankings and usefulness.
LangChain AI Discussion
In the LangChain AI discussion, users seek assistance for coding issues, discuss incorporating YouTube URLs using LangChain's documentation, request examples for creating custom tools and reactive agents, express interest in AI fine-tuning without a GPU, and share information on cost-effective local models like Hermes 7B and Haiku. Additionally, there are conversations about troubleshooting compatibility issues with Python versions, addressing language barriers in technical assistance, and exploring the capabilities of the Open Interpreter tool. The discussions reflect a collaborative effort to improve coding practices and optimize AI functionalities.
AI-Related Discussions on AI GPT Models
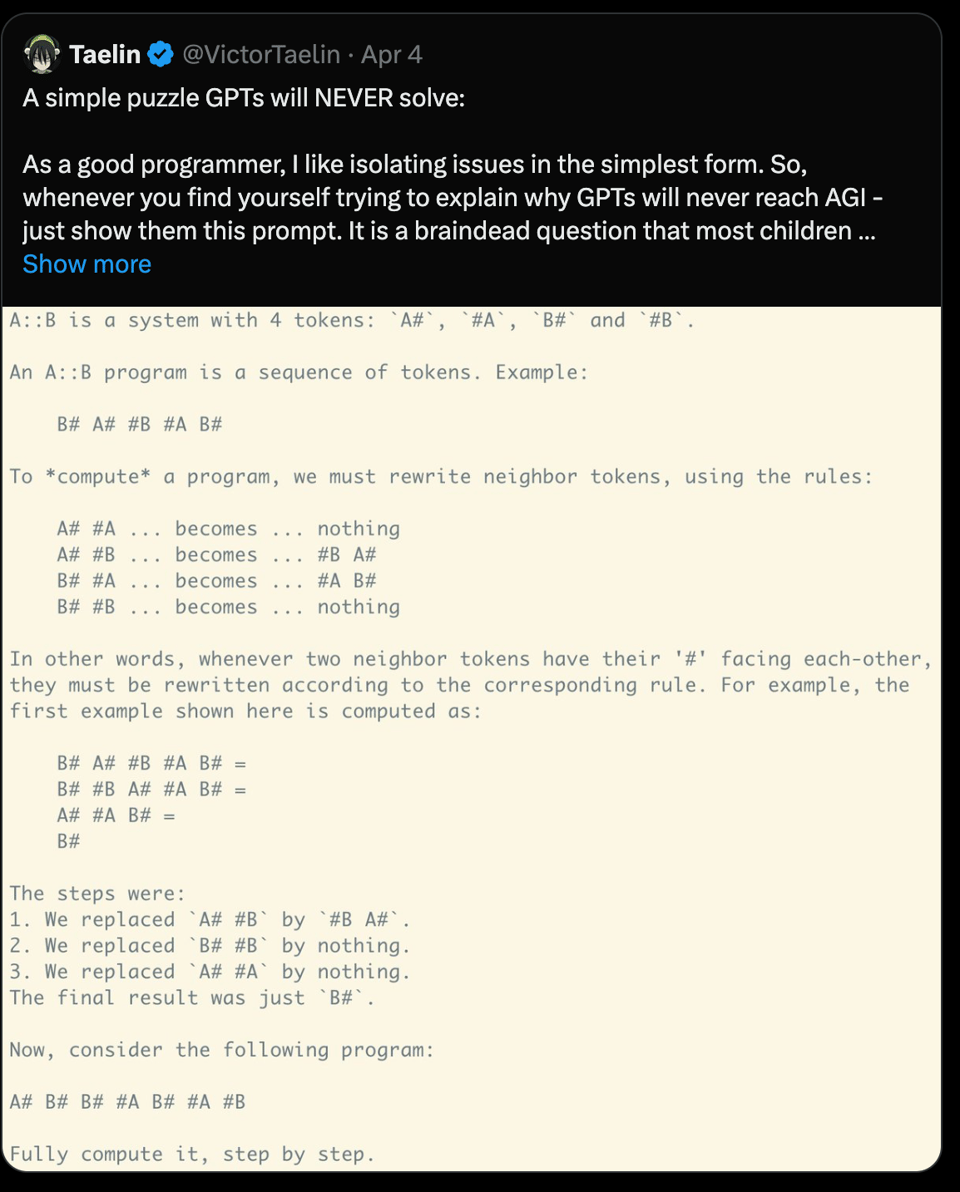
The Victor Taelin Prompt Challenge awarded a $10k prize after proving that GPT models can solve certain problem-solving tasks, despite initial claims. Stanford's CS336 course on language modeling and Groq's ambitious AI hardware goals were also discussed. LangChain released a new memory service for chatbots, while discussions on transformer architecture techniques and attention mechanisms were highlighted.
Expanded Tweets and Discussions on AI Engineering and Knowledge Tools
This section showcases a series of tweets from various personalities in the AI community, discussing topics such as the potential of GPTs, interaction combinators, and music videos related to AI. Additionally, there are announcements and discussions on upcoming courses, including one focusing on AI modalities. Furthermore, the Latent Space University's Inaugural Course is introduced, offering an AI Engineering course with a free introductory session. Another chat explores the benefits of using chat applications as knowledge bases and investing in tools like Obsidian-Copilot and fabric for AI-augmented human performance. The section also delves into ongoing conversations about various AI models, training techniques, and tools, highlighting the continuous growth and interest in the field of Artificial Intelligence.
Discussion on Open Model Weights and AI Regulation
The conversation in this section revolves around the societal impact of open foundation models, debating the need for safety thresholds and regulation on the release of AI technology. Participants express diverse views on the practicality of enforcing non-proliferation and the ethical responsibility in distributing AI. Additionally, members discuss the potential of language models to influence societal and democratic processes, considering the inevitability of AI advances and the challenges in regulation. Analogies are made to compare unrestricted AI to personal genies with societal consequences, highlighting skepticism towards enforcing usage restrictions. The increasing computational costs for training large models are noted, raising concerns about accessibility and affordability for the broader community. Towards the end, the concept of future models focusing on verification rather than generation is introduced, sparking curiosity about enhancing accessibility and reducing reliance on extensive models by shifting verifier knowledge during inference.
Models and Optimizations Discussions in CUDA Mode
In this section, various discussions and announcements related to models, fine-tuned models, and optimizations in CUDA Mode are highlighted. The interactions cover topics such as the societal impact of open foundation models, visualizing attention in transformers, utilization of fine-tuned models from platforms like lmsys and alpacaeval, the acknowledgment of OpenWeights models, and the commitment to categorize models visually for better understanding. Additionally, there are mentions of upcoming history talks on open language models, guides to open models like Salesforce's CodeGen series, and innovative approaches to enhancing language models' context length. The section also features discussions on fast tokenizers, AMD's open-source initiatives, launching a paper replication repository, setting up CUDA environments, and implementing sequence parallelism for language models. Lastly, there are debates on performance comparisons between custom CUDA and Triton kernels, training GPT-2 in pure C, and advancements in model quantization schemes like QuaRot for LLMs.
AI Research and Development Discussions
In this section, various discussions and developments in the field of AI research and development are presented. Some topics covered include exploring context parallelism, progress on variable length striped attention, questioning ring attention's memory usage, and much more. Participants engage in conversations about Triton visualization, GPU issues with llamafile, adjustments in memory scheduler integration, and the potential integration of Vulkan support. Additionally, advancements in tinygrad, Command-R's translation capabilities, Jamba's training speed caution, and downsized versions of Jamba architecture are discussed. The section highlights ongoing dialogues, queries, and developments in the realm of AI that are shaping the future of technology.
Skunkworks AI Innovations
In the Skunkworks AI channel, members discussed innovations like dynamic allocation of compute budgets within neural networks, new training techniques incorporating pause/think tokens, and neural input processing methods like reading input into a queue for flexible processing. Additionally, the channel focused on optimizing Haiku performance and shared results showing Anthropic's new tool outperforming GPT-4 Turbo on the Berkeley function calling benchmark.
FAQ
Q: What is LLaVA vision-language model undergoing a Rorschach test?
A: The LLaVA vision-language model underwent a 'Rorschach test' by being fed random image embeddings and analyzing the interpretations.
Q: What are the technical discussions around Claude's memory mechanism?
A: Engineers debated whether Claude retains information across sessions or if the semblance of memory is due to probabilistic modeling.
Q: What proposals were made post-DDoS attack in the Worldsim discussions?
A: Proposals were made for a Worldsim login system to thwart future threats and discussions of a 'pro' version to include more scenarios.
Q: What suggestions were made regarding chunking for RAG diversity?
A: Suggestions arose to pre-generate diverse datasets for RAG using a chunking script, alongside talk of creating complex multi-domain queries using Claude Opus.
Q: What GitHub repository was spotlighted for PDF-to-markdown conversion?
A: A GitHub repository, VikParuchuri/marker, was highlighted for its high-accuracy PDF-to-markdown conversion.
Q: What advancements were discussed in Canada's AI ambitions?
A: Advancements in Command R+, a scalable LLM by Cohere for businesses, and insights into Canada's strategy to champion global AI leadership were discussed.
Q: What is the focus of the George Hotz's Tinygrad Discord channel discussions?
A: Discussions in the Tinygrad Discord channel focused on topics such as reverting command queue, inaccuracies in TinyJIT tutorial, tutorials for contributing to tinygrad, redesigning roles, and MEC firmware architecture discussions.
Q: What discussions took place in the Mozilla AI Discord channel?
A: Discussions in the Mozilla AI Discord channel focused on identifying malicious versions of llamafile, local distribution of RAG-LLM, rectifying out-of-memory errors, and proposing Vulkan integration in llamafile.
Q: What announcements were made regarding SICP and Mojo in the AI community?
A: The classic textbook 'Structure and Interpretation of Computer Programs' is being ported to Mojo language, and a member is planning to rewrite popular algorithms in Mojo.
Q: What discussions were highlighted in the Discord channels for AI21 Labs, Datasette - LLM, Skunkworks AI, and LangChain AI?
A: Discussions in AI21 Labs covered Jamba models, in Datasette - LLM various topics like QNAP NAS setup and AI writing assistant 'Alter', in Skunkworks AI dynamic compute allocation and neural input processing methods, and in LangChain AI various topics like coding issues and troubleshooting compatibility.
Q: What updates were shared about the Aurora-M multilingual language model?
A: Updates about Aurora-M included its development following the U.S. Executive Order on AI, cross-lingual safety impact validation, peer recognition, and plans for future enhancements.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!